Robots should, in theory, be able to grab things of diverse sizes, forms, and compositions with effectiveness while executing missions and tasks in the actual world. However, the majority of robots can only now grip a limited range of things.
A novel machine learning model has recently been created by researchers at the Chinese Academy of Sciences and Peking University that may aid in improving the grasping capabilities of robots. This model, which was published in IEEE Transactions on Circuits and Systems for Video Technology, is intended to forecast grasps for things that a robot would come into contact with so that it can come up with the best techniques for grabbing such objects.
Robotic grasping is becoming more and more necessary in real-world applications, such as intelligent manufacturing, human-machine interaction, and domestic services, according to Junzhi Yu, one of the study’s authors, who spoke to Tech Xplore. “Finding the ideal grip for a target item is a key component of robotic grasping, which is called grasp detection. The checkerboard effects from unequal convolution result overlap in the decoder make conventional encoder-decoder grip detection methods less than ideal in terms of accuracy and efficiency. Furthermore, feature representation is often inadequate.”
The development of a model that would overcome the shortcomings of current grip detection frameworks was the main goal of the most recent study by Yu and his colleagues. They developed a pixel-wise grab detection methodology based on twin deconvolution and multi-dimensional attention, two well-known methods often used in computer vision applications, to achieve this.
Their approach was created to get rid of “checkerboard artefacts,” weird patterns that resemble checkerboards that are often seen in photos created by artificial neural networks. The researchers improved their model’s capacity to focus on certain elements of photos.
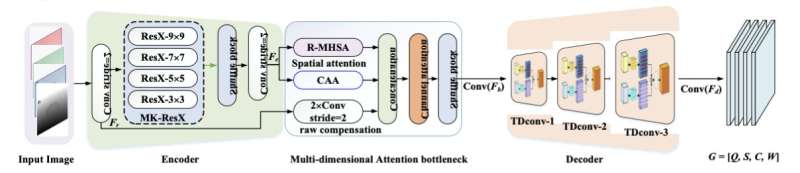
The suggested pixel-wise grab detection network is made up of a twin deconvolution-based decoder, a multi-dimensional attention bottleneck, and an encoder, according to Yu. The bottleneck module, which blends residual multi-head self-attention (R-MHSA), cross-amplitude attention (CAA), and raw compensation to better concentrate on the areas of interest, performs feature extraction from an input picture using the encoder.
The three parts of the bottleneck module created by the team provide three distinct outputs, which are then combined in a channel and subsequently modified to enhance feature representation. The model’s decoder then receives the final, improved “feature map” (i.e., a model that up-samples the feature map into a desirable output). By conducting three so-called cascaded twin deconvolutions, this decoder finally predicts the grasps that match to the input picture (processes to up-sample the feature map).
According to Yu, “our bottleneck module mines the inherent link between features and successfully fine-tunes features from the dimensions of space and channel.” “By adding a twin branch to the original transposed convolution branch, twin deconvolution in particular improves up-sampling. The problem of checkerboard artefacts is thereby resolved.”
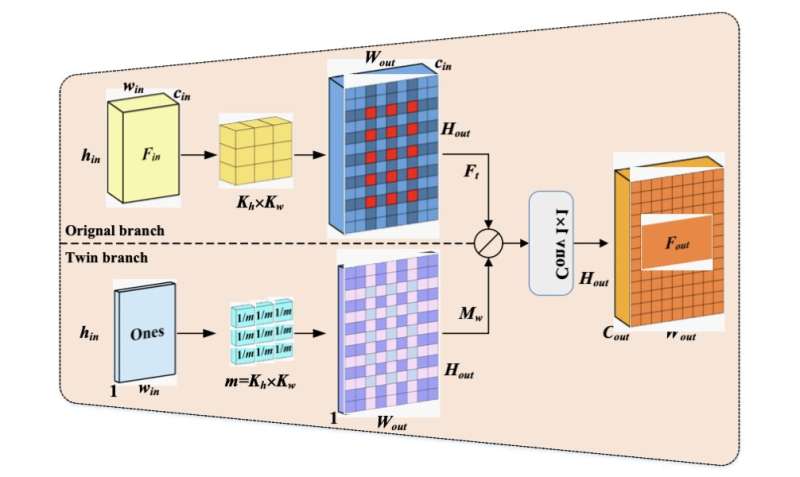
The researchers’ technique has the remarkable benefit of using twin deconvolutions, which add a twin branch to the original transposed convolution branch to enhance the model’s initial output. With this method, the model may get rid of unattractive checkerboard patterns in outputs.

It should be noticed that the unequal overlap of convolution results at various points is where the checkerboard artefacts come from, Yu stated. “In order to quantify the unequal overlap, a twin branch is thus added parallel to the original transposed convolution branch. More precisely, the feature map of the original transposed convolution is reweighted using the overlap degree matrix that is produced by the twin branch’s computation of the relative overlap differences across places.”
The novel pixel-wise grip detection technique demonstrated highly promising results in preliminary testing, as it was discovered to smooth the model’s original output and remove checkerboard artefacts. Thus, a high degree of grip detection accuracy was attained.
In the course of their research, Yu and his coworkers were also able to apply their method to other tasks that need pixel-wise detection. Their concept might therefore soon be used to solve additional computer vision issues in addition to perhaps improving the grasping capabilities of both current and newly created robots.
The suggested technique will be used with instance segmentation in real robot systems in Yu’s further efforts in order to improve grasp prediction. As an example, instance segmentation may be utilised to provide useful data about object location and profile, which is fed into twin deconvolutions of the decoder to enhance network performance even further.
You might also be interested in reading, The molecule, Keanu Reeves: A new active component derived from bacteria might protect plants




